��������Ƶѧϰ2017���Archsummitȫ��ܹ�ʦ����ݽ����������ʼ�
CTR(Cleick-Throug'xh Rate Prediction)�����Ԥ��
Ŀ¼
1. �����ѧϰ����CTRԤ��
2. ��ͳ����CTRԤ������
3. ���ѧϰ����ģ��
4. ���ѧϰCTRԤ��ģ��
5.��������˾���ѧϰCTR����
1. �����ѧϰ����CTRԤ��
���ѧϰ:��������ijɹ�
����ʶ������ʶ������ʶ�𡢻������롢���ת����ͼƬ����,�ȵȡ�

Ŀǰ�˹����ܷdz���,���ǿ���˼��һ��,�˹�����Ϊʲô��ô��?��������ʲô֧��?��ĭ��?������һ��ֵ����˼�ĵ㡣��ʵ�����֧�ž������ѧϰ��Ϊʲô���ѧϰ��֧������˹������ȳ��Ļ�ʯ�ͱ���?�㷨�������ѧϰ���Ӧ���Ǵ�ͳ���㷨��Ϊʲô���ѧϰ֮ǰ�˹�����û��������ô��?������ѧϰ�㷨,��дѧ�����ĵ���ʵ�ܹ����Ӧ��,��һ������,����ȷ�ʴﵽ85%����ͳ������������ȷ�ʻ���85%������,�����������Ӧ����ʵ��,��Ϊдѧ�������õIJ��Լ��ܸɾ�,��ʵ���е�����ȴ�Ƚϸ���,Ч����Ƚϲ�,���Դ�ͳ����������ء����ѧϰ����֮��,��Ҫ��ͼ����Ƶ������������ͻ��,�봫ͳ�����Ƚ����ʵ�����,����ȷ�ȿ��Դﵽ90%+,������ء�
��ͼ����������Ϊһ��,��������ͼƬ����Ƶ����Ƶ�����������������NLP,���ѧϰ��NLP����Ҳ����������ʹ֮ȷ����������,����û��ǰ������������
�������һ��ͼ,������������ģ�͡��˹������������˵,�и�ȱ��,�˹��Dz����������ԵĶ���,�������������ࡣ�������ǿ�������һ�¡�����GAN�Ŀ��ٷ�չ,��ȫ���������һ������,���綯��Ƭ,ֻҪ���Ǹ������¹���,���������������������Ƭ,������Ҫ��������Ҫһ��һ��ȥ������Ȼ���ڻ�������,���Ǽ���֮�����п��ܵġ�����˵����ģ�ͻ���һ���Ƚ��з�չǰ���ķ���
CTR�����Ӧ��

CTR��ʲô?����:�������һ���û�user,����һ����Ʒproduct,��������,ʲô�龰��,���˿����������Ʒ,CTR�����������������,�û���������ҵ������Ʒ,��������Ʒ�ĸ����ж��,��������û��Ƽ������Ʒ,�����Ӱ,�û�ῴ,���ĸ��ʶ��
��ͼ��,��һ��,������,Ŀǰ�Ĵ��ͻ�������˾��沿�����ľ���CTR���ڶ���,�Ƽ�ϵͳ,�Ƽ�ϵͳҲ���Ա�ת��Ϊһ��CTR����,һ�����Ƽ�ϵͳ�õķ����о���ֽ⡢item-based��KNN��user-based��KNN�ȡ�������,��Ϣ������,����ٶȡ�ͷ������,������Ϣ����������,���ע�˺ܶ���,���Ƿ��˺ܶ���Ϣ,��ô�����ȸ���չʾ��Щ,����ܻ������
CTR������ص�
- ������ɢ����
- ������ά��ϡ������
- ��������:������϶���Ч���dz��ؼ�(����:����1:˫11,����2:Ů��)
2. ��ͳ����CTRԤ������
��CTRԤ�����õķ�����Ҫ��:���ع�(LR)��GBDT��ģ�͡�LR+GBDT��FMģ�͡����ӷֽ�������ѧϰģ�͡�
����ģ��:˼·������

����ģ��,������CTRԤ��,Ӧ�������л���ѧϰģ������ķ�������ʽ��ͼ����Ӧͼ������ɫֱ�ߡ�
�˴�LRģ��������ģ�͵Ļ�����������Sigmoid,�����ֵѹ����[0,1],���ս��ֵԽ��,Խ�п��ܹ������ǵ���Ʒ,�÷�Խ��,Խ��������
Ŀǰ�ܶ˾���ϻ���LRģ��,��Ϊ���кܶ��ŵ�������ģ�Ͳ����е�:���ɽ���(�Ӹ�����ֻҪ������ֵ����)������չ��Ч�ʸߡ��ײ��С�
ȱ��:���Բ���������ϡ�(û�����,û�з�����������֮��Ĺ�ϵ)
����ģ�Ľ�:�����������(�Ľ����Բ����������)

����:���������������
ȱ��:����������
FMģ��(�Ľ�����������)


GBDTģ��
Gradient Boosting Decision Tree:�����ľ������㷨,��þ���������,���������ľ���ֵ�ۼӵó�Ԥ��ֵ��GBDT�кܶ�����,������Ϊ:MART(Multiple Additive Regression Tree)��GBRT(Gradient Boosting Regression Tree)��TreeLink�ȡ�
����:
Ԥ���Ƿ�ϲ������Ϸ

LR+GBDT
Facebook��2014�����;����LR��GBDT���Ե�����(GBDT������Ч���������Feature Set;��Feature Set����LRģ����);Ŀǰ�㷺ʹ���ڸ���������˾����ϵͳ�С�

��ĿǰЧ����õ�ģ��֮һ��
GBDT+FM
�������+�ٶ���2014�����;����GBDT��FM���Ե�����(GBDT��������Ч���������Feature Set;��Feature Set����FMģ����);GBFM��̰�IJ���ѡ�����������
���Ǿ���һ������:FM�������������Ѿ����,ΪʲôҪ���һ��,������ȥ��?��:����FM��n������,�����������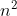 ,����̫��,Ч��̫��,�����д���������������õġ�����������GBDTѡ������õ�����,���͵�FM��,�����������Ч�ʡ� ,����̫��,Ч��̫��,�����д���������������õġ�����������GBDTѡ������õ�����,���͵�FM��,�����������Ч�ʡ�
3. ���ѧϰ����ģ��
ǰ��������(MLP)

������Ԫ����һ����Ԫ�����ӹ�ϵ:ȫ���ӡ�
ǰ��������(MLP):����ڵ�

������Ԫ����ʲô?����ͼ,������:��һ��,��������м�Ȩ���;�ڶ���,���з����Ա任��
ǰ��������(MLP):�����


ReLU��Ŀǰ��õļ������
CNN:LeNet-5����ṹ

����:����(Convolution),�ػ�(Pooling)��
CNN:������

�þ����˽��м�Ȩ���+�ü�������з����Ա任��
һ�������˲���һ������,��256�������˾�����������256�������ġ�
CNN:MaxPooling��

ȡ���ֵ��
���ٲ�����,��ֹ����ϡ�
CNN:ѧ����ʲô����?

��ײ�:�߶�
��һ��:����
�ٸ߲�:ģʽ
�ٸ߲�:����
�ٸ߲�:��������
�ص�:������
RNN

RNN��Ҫ�����������,��Ҫ����NLP�����ſ���ǰ��������һ��,��һ���ľ�������ᴫ��,�ұ������������ԭ�������뻹������һ������������
˫��RNN

��Ȼ������,������֪������ʵĴ���,��ǰ���ʵ�ǰ�ʶ�����Ҫ,˫��RNN�����ṩǰ��˫����Ϣ,�������жϡ�������ֻ���ṩǰ�����Ϣ��
LSTM

RNN�ĸĽ���
����3����:������(����������Ϣ���߶ȴ���)��������(��һ�����㴫�����Ϣ��)�������(�����������Ϣ��)��
˫�����LSTM

4. ���ѧϰCTRԤ��ģ��
���ѧϰCTRģ��Ҫ����ļ����ؼ�����
- CTR�����ص�:������ɢ�����ı�ʾ���⡾����������Ȼ������������ֵ,����ͼƬ����ֵ0~255��
- CTR�����ص�:��ο��ٴ���������ά��ϡ������?(OneHot 2 Dense)
- ��������:��δ��ֹ����Զ�?(���ѧϰ������:end to end)
- ��������:��β���ͱ��������������?(FM���������绯)
- ��������:��β���ͱ�������������?(����Deep����)
CTR�������������
��������:
- ����,����,����......
- �ʺ�DNN����
��ɢ����:
- ְҵ,�Ա�,��ҵѧУ......
- ���ʺ�DNN��������ν�������ɢ������������������?��
��ɢ���������DNN���Դ���?
ֱ��˼·:��ɢ����ʹ��Onehot����

Ȼ��,��������!!!

��Ϊ:��������ճ������е�С��ģ�����ǿ��Ե�,�������ʵ�еĴ��ģ�����Dz���ȡ�ġ�
Onehot��ΪDNN���������:CTRԤ�������ﲻ����

������ģ̫���ˡ��������50�ڲ���,�Ѹ㡣
���˼·:OneHot��Dense��Vector

����˼��:����ȫ����,�ֶ���֮��
�γ�DNN�ṹ

��ͼ�����ѧϰ��CTR����ĵ��ͽṹ��
�ټ�����������

ͨ�õ����ģ�ͽṹ

DNN������������,����......

������������������,��Ϊʲô��Ҫ����������?��Ϊ��CTR����Ҫ�ѵͽ���(����)����ϵ�����ģ��
�ѵͽ�������ϵ�����ģ
������Ҫ:����һ���������ĵͽ��������ģ��

FM��FunctionҪ���ֵ�˼��:
- Function:
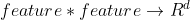 �� �� - Function����������ı�����ʽ:�����������ں�
- Function�ܹ�����FM��˼��:

�ѵͽ��������ģ�Ͳ�������ṹ��

�����������ںϽṹ֮һ:���нṹ

���нṹʵ��:Deep FMģ��(Դ�Ի�Ϊ)

���нṹʵ��:Deep&Crossģ��
FM Function = Cross Network = ResNet

���нṹʵ��:Wide&Deepģ��

Wide&Deep��Եͼ�,������:
- Wide����LRģ��,û��FM���
- ������ͬ������ṹ
- Wide�������ֹ�����+Cross����
���������ںϽṹ֮��:���нṹ

���нṹʵ��:PNNģ��

���нṹʵ��:NFMģ��

���нṹʵ��:AFMģ��
���NFMģ��,ֻ�Ƕ���������������Attention��

ģ��ѵ�����Ż�:Dense���Ԥѵ��

ģ��ѵ�����Ż�:Deep������������ṹ

����������νṹ(����������ԪԽ��Խ��)��
ƽ�нṹ�������νṹЧ���ȽϺá�
ģ��ѵ�����Ż�:Deep��������IJ���

���������Ƚϳ���,Ч���Ѿ�OK�ˡ�
5.��������˾���ѧϰCTR����
Google:Youtube��Ƶ�Ƽ�
Google 2016�깤��:
- ����:Deep Neural Networks for YouTube Recommendations
- ������,Ч�����ڴ�ͳģ��
��Ҫ��ע:
ϵͳ�ṹ:

�dz�ͨ�õ�ʵ������Ľṹ,������:��һ��:��ɸ(��ͼ1),�Ӵ���������,���缸��������ҳ���ǧ���п��ܵı�ѡ��ġ��ڶ���:ranking,����,��ѡ(��ͼ2)��


���������ܵ�Ӱ��:

����Ͱ�:Deep Interest Network
��������2017�깤��:
- ����:Deep Interest Network for Click-Through Rate Prediction
- ������,Ч���������ڴ�ͳģ��
��Ҫ��ע:
- ��Ȥ�Ķ�����
- �ֲ�����(Local Activation)
չʾ���ϵͳ:

ʹ������:

��ģ��:

DINģ��:

�ֲ�����(Local Activation):

�����̳�:Telepath
����2017�깤��:
- ����:Telepath: Understanding Users from a Human Vision Perspective in Large-scale Recommender Systems
- ������,Ч���������ڴ�ͳģ��
��Ҫ��ע:
- �����Ƽ����
- �ں�ͼƬ����Ϊ�ȸ�����Ϣ
�Ƽ�ϵͳ����ܹ�ͼ:

Telepath����ṹ:

�Ӿ�����item���ӻ�:

���߶Ա�Ч��:

| 





