д��ǰ��
����һƪ���ڿ���ѧϰ������,�����Ȩ���Լ��ıʼ�,��ЩӢ��Ϊ���Լ���������ܷ���IJ�ȷ,�����ʲô��������λ���ߴͽ�!!!
����
������������Ѿ����к�ǿ�ıƽ�����,���Ǵֵ�������Ϊ�����ij��������ӵĽṹ,ѵ�����̵�ʱ�俪���ܴ��Ҹ��ӵĽṹ�������������Ϸ�����Ϊ��ѵ����������,�����ĺܶ�ļ�����Դ,����,�ô�ͳ�����ݶ��½������в���ѧϰ,ģ�ͻ��ܵ���������Ӱ��,Ҳ�����������������;ֲ�����,�����û��һ��ģ���ܹ���������������?
��������ƪ���������Ƚ�����һ���������������������(RVFLNN),����ͼ:

�������ͼ,���ڿ�RVFLNN��������,�������һ��������,�м�Ľ���ǿ��,����Ľ�����㡣�ȼĽ���һ���������,ֻ���м��һ����з���������,��ǿ�ڵ���ͨ��x���� ������õ���, ������õ���, ��������ɵ�,���ұ��ֲ���,�������ڵ����ǿ�ڵ㶼������ڵ��������ӡ����ǿ��Ժ����ԵĿ���,����������ʲô�ص�?������Щ�������,�����������ٺܶࡣ������,���ǰ���ǿ�ڵ�ŵ��������һ���λ�á�����ͼ,���ǻ����Է���,��������ṹ���ص���ǿ��� ��������ɵ�,���ұ��ֲ���,�������ڵ����ǿ�ڵ㶼������ڵ��������ӡ����ǿ��Ժ����ԵĿ���,����������ʲô�ص�?������Щ�������,�����������ٺܶࡣ������,���ǰ���ǿ�ڵ�ŵ��������һ���λ�á�����ͼ,���ǻ����Է���,��������ṹ���ص���ǿ���

��ô����,��������ѧʽ�ӱ�ʾһ���������: ������ ������![A = [X|\xi (XW_{h}+\beta _{h})]](https://beijingoptbbs.oss-cn-beijing.aliyuncs.com/cs/5606289-e7ebb91e1c69908532b02b66172d1803.latex) ���������,����֪������ʲô?��Ȼ,A��֪,������Y��֪�����,���Ȩ��W,����ζ�Ŵ�ɡ���Ȼ ���������,����֪������ʲô?��Ȼ,A��֪,������Y��֪�����,���Ȩ��W,����ζ�Ŵ�ɡ���Ȼ , , ��A��α��,��ΪA��һ������,���������������α������W�������ֱ�ƽ��������,α�����˵�ǽ��Ȩ�ص�һ���dz������ݵķ����� ��A��α��,��ΪA��һ������,���������������α������W�������ֱ�ƽ��������,α�����˵�ǽ��Ȩ�ص�һ���dz������ݵķ�����
������������,�����
�����Ƚ���һ������ֵ�ֽ�(SVD)����������ֵ�ֽ�ο�:https://www.cnblogs.com/pinard/p/6251584.html��ƪ����
һ������A���Էֽ�Ϊ������ʽ:
��ʽ��A��mn�ľ���,U��mm�ľ���,D��mn�ľ���,V��nn�ľ���
U����:
������ǽ�A��ת�ú�A������˷�,��ô��õ�n��n��һ������ 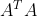 ��������������������ֵ����������,�������е������������һ������,���nn�ľ������V��һ�����ǽ�V�е�ÿ��������������A�������������� ��������������������ֵ����������,�������е������������һ������,���nn�ľ������V��һ�����ǽ�V�е�ÿ��������������A��������������
ͬ��,������ǽ�A��A��ת��������˷�,�ͻ�õ�һ��mm�ķ���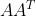 ,�Դ˷������������ֵ����������,�������������������ɵľ���,����U����D�����������ֵ,����Ԫ�ض���0������ֵ������������ֵ�����š� ,�Դ˷������������ֵ����������,�������������������ɵľ���,����U����D�����������ֵ,����Ԫ�ض���0������ֵ������������ֵ�����š�
��ô,���ֽ��Ժ�,��ʲô������?��D������,����ֵ�ǴӴ�С�����ŵ�,��������ֵ�ļ����ر�Ŀ�,���,���ǾͿ��ѱ� С������ֵ������,��ȡ���������ֵ,���������ܹ����� С������ֵ������,��ȡ���������ֵ,���������ܹ�����

����ͼ��ʾ,���ǿ��Խ�A����ϴ�ľ���,��ͼ�к�ɫȦ�е�mr��С��������ʾ,�ﵽ��Ŀ�ġ�
����,�����ѧϰ���Ȿ����(����)�������:

������Ϊֹ,�ؼ���α����ݹ�ʽ�����������,��W = Y,��˾Ϳ��Եõ�W���Ȩ�ء�Ϊ�˵õ����ȶ���Ȩ��,��ô���߲�������ع��㷨��

��ع���ʵ��������С���˷��Ļ�����,����һ��������,����С���˷�Ҫ��֤����,��˼�һ����ķ������֤���������档

������Ϊֹ,���һ�н�չ˳��,��������Ѿ��ܹ�Ԥ�������������ˡ���ô�������Ѿ���õ�����,���ܹ����ıƽ�������Ҫ�Ľ����ô��?�������ֻ����ǿ�ڵ��з���������,���,�����Dz��ǿ��Լ�һ����ǿ�ڵ����ﵽ������Ҫ��Ч����

����ͼ��ʾ,�������Ѿ�ѵ���õ�������,����һ��a��������ô �ͱ���� �ͱ���� ������ = [|a]��������,Ȩ�ؾ͵���������,�������������˵,���� ������ = [|a]��������,Ȩ�ؾ͵���������,�������������˵,���� ,������ع��㷨,�Ǽ��㿪�������������Ҳ������������и����Ĺ�ʽ,����ֱ������һ�ε�α��,����������չ���α��,��ʽ����: ,������ع��㷨,�Ǽ��㿪�������������Ҳ������������и����Ĺ�ʽ,����ֱ������һ�ε�α��,����������չ���α��,��ʽ����:

�����ʽ���Ƶ�,���ǿ���https://blog.csdn.net/itnerd/article/details/104360595��ƪ���¡��Ƶ������ʽ�ĺ���˼�������һ������,���ⷽ������⡣
����Ϊֹ,���ǹ����������������������(RVFLNN)�����ݾͽ������ˡ�����ѧϰϵͳ(BLS)��ʵ�����������������������(RVFLNN)�Ļ�����,��ԭʼ������,ת���ӳ�䡣�ܼ�,������ ���ʽ����������������ӳ�䡣��ԭʼ����X���Z,����ṹ���ǿ���ѧϰ�Ļ����ṹ������ͼ: ���ʽ����������������ӳ�䡣��ԭʼ����X���Z,����ṹ���ǿ���ѧϰ�Ļ����ṹ������ͼ:

����ѧϰ���ֽṹ�ȼ۵�֤��
�������ͼ,�ǿ���ѧϰ��һ�ֽṹ,����һ�ֽṹ:

,�Ҿ��������е�ͼ�ƺ���ֱ̫��,�Ҽ��ԵĻ�һ��ͼ:

��һ�ֽṹ����ͼ����:

��ô�����ֽṹ�������Զ���,������ǿ�ڵ�ļ���,һ�ֽṹ�Ǹ�������ӳ��ڵ�������һ����ǿ�ڵ�,����һ�ֽṹ�Ǹ���һ��ӳ��ڵ����һ����ǿ�ڵ㡣֮������֤���������ֽṹ������һ���������ǵȼ۵�,֤������:
�����ȿ���һ�ַ�ʽ:���Ǽ�ij��ӳ��ڵ�Ϊ ,i��1...n,ÿ����kά����ô�����Թ���nk���ڵ㡣��ǿ�ڵ�Ϊ ,i��1...n,ÿ����kά����ô�����Թ���nk���ڵ㡣��ǿ�ڵ�Ϊ ,j��1...m,ÿ����qά�ȡ������Թ���qm����ǿ�ڵ㡣 ,j��1...m,ÿ����qά�ȡ������Թ���qm����ǿ�ڵ㡣
ͬ��,�ڶ��ַ�ʽij��ӳ��ڵ�Ϊ ,i��1...n,ÿ����kά����ǿ�ڵ�Ϊ ,i��1...n,ÿ����kά����ǿ�ڵ�Ϊ ,j��1...n,ÿ���� ,j��1...n,ÿ���� ά�ȡ� ά�ȡ�
��ô,���qm = n,��ô,�����ֽṹ���ǵȼ۵ġ���Ȼ,�������������,˵����ǿ�ڵ�Ĺ�ģ��һ������,��ôֻ��Ҫ֤������һ����Ӧ����ǿ�ڵ㶼�ȼ�,��ô��������͵ȼۡ�
���Ǽ� �����������е�����һ������,��Ȼ����һ��һά�ĺ������� �����������е�����һ������,��Ȼ����һ��һά�ĺ������� (Ȩ�غ�ƫ��)���������ͬһ����˹�ֲ��в��������ݡ���ô,�ȿ���һ�ַ�ʽ,����һ������ص���ǿ�ڵ���Ա�ʾ����: (Ȩ�غ�ƫ��)���������ͬһ����˹�ֲ��в��������ݡ���ô,�ȿ���һ�ַ�ʽ,����һ������ص���ǿ�ڵ���Ա�ʾ����:
  (�Ƚ�����ӳ��,�پ�����ǿ) (�Ƚ�����ӳ��,�پ�����ǿ)
��ʽ�и�������Ķ������Ծ��忴�����еĽ���,�����к���ȷ�Ľ����ˡ�

����һ��������һ��������,������������˼��ɵõ���

��һ����Լ����,��ʵ���Ը�����˼������,
���ʽ�Ӻ���������,С�궼���� ,˵�������������Ȩ�غ�ƫ�ö�������ص�,����һ�� ,˵�������������Ȩ�غ�ƫ�ö�������ص�,����һ��
ȴ���ٺ���С��,�����Ȩ�غ�ƫ�ö������´Ӹ�˹�ֲ��в���������,��Ȼ���ǴӸ�˹�ֲ���ȡ������,�ǾͲ������,����Լ���ڡ�

�������һ��,������һ��������ص���ǿ�ڵ�,�����������������ʽ�����㡣
��һ�ַ�ʽ�����,��ô�ڶ��ַ�ʽͬ��

���ú��Ȧס�IJ���,Ӧ�����д���
�������ַ�ʽ����ǿ�ڵ�������¹�ϵ

��Ȼ,���ʹ�ù�һ��,����ȫ�ȼ۵ġ��ٸ�������,һ������(1,2,3,4),��һ������(2,4,6,8)�����ʹ�ù�һ��,

��ô��һ�����ͳ���(0,1/3,2/3,1),�ڶ���Ҳ��(0,1/3,2/3,1)����Ȼ�ȼ�
����������Ŀ���ѧϰ�ṹ�Ժ�,��������һ�¿���ѧϰ������ѧϰ������ѧϰҲ���������,����һһ���ܡ�
����ѧϰ
(1)������ǿ�ڵ�
���ǵĿ���ѧϰ���粻���ܹ��������ǵ���Ҫ��ȷ��ʱ��,���ǿ���ͨ����ǿ�ڵ������õıƽ�,�����Ѿ����ܹ�����һ��a
��ô����α��,������������ֱ���Դ�����:

(2)����ӳ��ڵ�
����ǿ�ڵ������,���ܹ�ʹ�����кܺõ�Ч��ʱ��,������������ȡû������,��ô���ǾͿ�������ӳ��ڵ㡣ͬ��,���Ӻ���¾����α���Դ�����:

(3)�����µ�����
�µ���������,���Ǻ����������,��ôͨ�����������ݼ�������Ȩ��,�Դ�����:

����ļ�
��������������ǿ�ڵ�,ӳ��ڵ��,���ܴﵽ��������Ҫ��Ч��,����Ҳ��������������ķ��ա���ô��ô���������һ���ļ�,�õ��ı���������ܵ�SVD����
������ṹ�ַ��������:
(1)��ӳ��ڵ�

�ϽDZ��P��,��ʾ����ȡǰr������ֵ�ļ�ľ���
(2)���Ѿ�����õ���ǿ�ڵ�
�����ʽ���Դ�����,�ﵽ��Ч����

(3)������һ����ǿ�ڵ������

��Ϊ����������ǿ�ڵ�,���Լ���ɺ�û����,��Ҫ��������ѧϰ��
(3)����ɺ������

ʵ��

����ʵ���е�һ����,���ǿ��Ժ����ԵĿ�������ѧϰ�ĸ�Ч��
����
��ƪ����,��ʵ����ϡ�������,ADMM�㷨���lasso����,�����ӹ�ʽû����ϸ����,�Ҿ�����ƪ���°����Ķ���ʮ�ֹ㲩,��ƪ����ֵ����ѧϰ�ĵط�ȷʵ���кܶ�,��ʹд��ƪ���͵Ĺ�����,���������µ��ջ�,�¹ʶ�֪��,����Ϊʦ�ӡ�������ƪ�����е������Ƿȱ,���ͷ�ܽ�,ʮ���б�Ҫ������Ҫ��л�ҵ�,��лʵ���ҵĸ�λ�ֵܽ��ð����ҽ�����⡣
�ο���һЩ��������:
admm�㷨��lasso�ع顢�����ӹ�ʽ:
https://zhuanlan.zhihu.com/p/106896627
https://zhuanlan.zhihu.com/p/103161094
�ֿ������α��:
https://blog.csdn.net/itnerd/article/details/104360595
����ṹ
https://blog.csdn.net/Liangjun_Feng/article/details/80541689 | 





