RNN(ѭ��������)
һ��ǰ��
ѭ��������(recurrent neural network)Դ����1982����Saratha Sathasivam ����Ļ��շƶ������硣
��ͳ�Ļ���ѧϰ�㷨�dz��������˹���ȡ������,ʹ�û��ڴ�ͳ����ѧϰ��ͼ��ʶ������ʶ���Լ���Ȼ���Դ������������������ȡ��ƿ����������ȫ����������ķ���Ҳ���ڲ���̫�ࡢ������������ʱ��������Ϣ�����⡣���Ÿ�����Ч��ѭ��������ṹ���������,ѭ���������ھ������е�ʱ����Ϣ�Լ�������Ϣ����ȱ����������������,��������ʶ������ģ�͡����������Լ�ʱ������ȷ���ʵ����ͻ�ơ�
��������
1�����Զ���:
ѭ��������(Recurrent Neural Network, RNN)��һ��������(sequence)����Ϊ����,�����е��ݽ���������ݹ�(recursion)�����нڵ�(ѭ����Ԫ)����ʽ���ӵ��ݹ�������(recursive neural network)��
2����ѧ����:
����Ϊ  ��Ӧ������״̬ ��Ӧ������״̬ 
���Ϊ 
�� RNN ��������̿��Ա�ʾΪ:



����  ��Ϊ����, ��Ϊ����, Ϊ ʱ�䲽(time-step),�� Ϊ ʱ�䲽(time-step),��  ��ʾ�����,һ��Ϊ ��ʾ�����,һ��Ϊ  ������ ������
����RNN ģ��
ѭ�����������Ҫ��;��������Ԥ��������������ȫ����������ģ��������������ģ����,����ṹ���Ǵ�����㵽���ز��ٵ������,�����֮����ȫ���ӻ�ȫ���ӵ�,��ÿ��֮��Ľڵ��������ӵġ���������һ������,���ҪԤ����ӵ���һ��������ʲô��һ����Ҫ�õ���ǰ�����Լ�ǰ��ĵ���,��Ϊ������ǰ�ʲ����Ƕ����ġ�����,��ǰ������ "��",ǰһ�������� "���",��ô��һ�����ʺܴ������ "��"��ѭ�����������Դ����Ϊ�˿̻�һ�����е�ǰ�������֮ǰ��Ϣ�Ĺ�ϵ��������ṹ��,ѭ������������֮ǰ����Ϣ,������֮ǰ����ϢӰ�����ڵ�������Ҳ����˵,ѭ������������ز�֮��Ľڵ��������ӵ�,���ز�����벻���������������,��������ʱ�����ز�������
1��RNN �ṹͼ����:


��ͼ:RNN ģ��δ��ʱ������չ����ͼ��
��ͼ:RNN ģ�Ͱ�ʱ������չ����ͼ��
ͼ������������������ ���� RNN ��ģ�͡�����:
(1) ���������������� ʱѵ�����������롣 ͬ����, ���������������� ʱѵ�����������롣 ͬ����, �� ��  ���������������� ����������������  �� ��  ʱѵ�����������롣 ʱѵ�����������롣
(2) ���������������� ʱģ�͵�����״̬�� �� �� ���������������� ʱģ�͵�����״̬�� �� ��  ��ͬ������ ��ͬ������
(3) ���������������� ʱģ�͵������ ֻ��ģ�͵�ǰ������״̬ ������ ���������������� ʱģ�͵������ ֻ��ģ�͵�ǰ������״̬ ������
2�����ü���
(1) �ӷ�(addition)

(2) �˷�(multiplication)

(3) ����(concatenate)

3�� ������ͼ

4����������(parameter sharing)

��ͼ:��ͨ������,������������
��ͼ:RNN ������,����������
5��˫�� RNN(Bidirectional RNNs)
ʱ�䲽 ���������ȡ����֮ǰʱ�̵���Ϣ,��ȡ����δ��ʱ�̵���Ϣ,��������˫�� RNN����ͼҪԤ��һ�仰�м䶪ʧ��һ������,��ʱֻ�������Dz��е�,��Ҫ�鿴������˫�� RNN ��ʵ������������ӵ� RNN��
 
����ͼ���Կ���,ÿ��ʱ����һ������,���ز��������ڵ�(����),һ�� �����������,��һ��  ���з������,�������������ֵ������ ���з������,�������������ֵ������
���㹫ʽ:



��ʽ���п��Կ���,�������ͷ�������Ȩ�ز�����,��һ�������˫�� RNN һ����6��Ȩ�ؾ���: ����: �� �� �� �� ;����: ;����: �� ��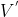 �� ��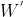 ;����Ȩ������: ;����Ȩ������: �� ��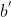 �� �� �� ��
Ӧ�ó���:
a��������ա�
b���������롣
6�����˫�� RNN(Deep RNNS)
��˫��RNN����,ֻ��ÿ��ʱ���������������Խ��,ѧϰ����Խǿ,��Ҳ��Ҫ����ѵ�����ݡ�
�������ͨ DNN ���ز�������ϰٲ�֮��,�� RNN �� 3 ��������,��Ϊ��ʱ��ά��,��������൱��,��ʹֻ�к��ٵ����ز㡣 ͨ�����������: ,���ϱȽ���IJ�,������Щ����ˮƽ�����ϲ��������� ,���ϱȽ���IJ�,������Щ����ˮƽ�����ϲ���������
���˫�� RNN ������һ�ֽṹͼ����:
  
�������ϱ�  ����ʾ�� ��,��ͼ�е�����˳��������㹫ʽ: ����ʾ�� ��,��ͼ�е�����˳��������㹫ʽ:






�ġ�RNN ������ģ�͵IJ�ͬ�ṹ
RNN( Recurrent Neural Network ѭ��(�ݹ�)������) ���˵Ĵ��Լ����ࡣ���ǵ��κξ������뷨���Ǹ�������֮ǰ�Ѿ�ѧ���Ķ��������ġ�RNN ͨ�������ͼ������,�ܹ��������ⳤ�ȵ�����,�ڼܹ��ϱ�ǰ�����������������������Ľṹ,���IJ���Ҳ����Ϊ�˽�����������Ӧ�ö����ġ�������� RNN �ļ��ֲ�ͬ�Ľṹ:
1��one-to-one RNN �ṹ
 
���� RNN ������ĵ�������,������  ,�����任 ,�����任  �� ����� �õ���� �� �� ����� �õ���� ��
2��one-to-many RNN �ṹ
 
һ�Զ�ṹ:���벻������,���Ϊ����,ֻ�����п�ʼʱ����������㡣����:��ͼ˵��,��ͼƬ��������������,������� ��ͼ�������,�����һ�ξ���,������ ��
��һ�ֽṹ:����Ϣ���� ��Ϊÿһ�ε�����,����ͼ��ʾ:

��ͼҲ��������ͼ�ȼ۱�ʾ:

Ӧ�ó���:
(1)��ͼ����������(image caption),��ʱ�������ͼ�������,�����Ϊһ�ξ���(����)��
(2)������������Ի����ֵȡ�
3��many-to-one RNN �ṹ
 
���һ�ṹ:����һ������,���һ��������ֵ��
Ӧ�ó���:
(1)���ֽṹͨ�������������з������⡣������һ�������б��������������һ��һ�������ж��������������һ����Ƶ���ж�������Ƶ���ȡ�
4��many-to-many RNN �ṹ
(1)���� == ���

��Զ��� RNN �����Ľṹ,�����롢������ǵȳ����������ݡ���������  ,ÿ�� ,ÿ��  Ϊһ�����ʵĴ������� Ϊһ�����ʵĴ�������

RNN �����������ز�(hidden state),���ز������������������������ȡ����,������ת��Ϊ���������ͼ��ʾ, �ļ����������� �ļ�����������  �� ��  ,�����任 ,�����任  �� ����� �õ���� �� �� ����� �õ���� ��

 �ļ���� ����,�ڼ���ʱ,ÿһ��ʹ�õIJ��� �ļ���� ����,�ڼ���ʱ,ÿһ��ʹ�õIJ���  ����һ����,Ҳ����˵ÿ������IJ������ǹ�����,���� RNN ��һ����Ҫ�ص�:���������� ����һ����,Ҳ����˵ÿ������IJ������ǹ�����,���� RNN ��һ����Ҫ�ص�:����������

���μ���ʣ�µ�  ,ʹ����ͬ�IJ��� �� ,ʹ����ͬ�IJ��� ��

���ֵ�ļ���,��ͨ��  ���м���,�� ���м���,��  �����ֵ��ͨ���� ����һ�� �����ֵ��ͨ���� ����һ��  �任�ͼ���� �任�ͼ����  �õ���� �� �õ���� ��

ʣ�µ�  �����ʹ�����Ƶķ�ʽ���м��㡣 �����ʹ�����Ƶķ�ʽ���м��㡣

Ӧ�г���:
a�����б�ע��
b��������Ƶ��ÿһ֡�ķ����ǩ,��ÿһ֡���м���,�����������еȳ���
(2)���� !== ���

Ӧ�ó���:
a����������,����һ���ı�,�����һ�����Ե��ı��� | 





